Some tweets:
https://x.com/BenjaminAUdell
Table of contents & month archives:
Archives
Posts on which I've worked lately at Tetrast2:
I disbelieve in numerology and it bores me. No paranormalism, no synchronicity claims, etc., here.
The label “the Tetrast” is partly in fun at my inclination to make philosophy on the seemingly threadbare theme of a 4-fold pattern. I developed most of my 4-folds independently of Peirce's 3-folds, many of them before I came to read Peirce. The semiotic tetrad and related sign classes are the exceptions.
Adjunct blogs:
• The Tetrast2 - Speculation Lounge
• The Tetrast3 - Bits
• What of these other fours?
About Me

- Name: The Tetrast
- Location: Woodside, New York, United States

I’m Ben UdeIΙ. Quadruplicity drinks procrastination, quoth Bertrand Russell making sense, and the best proof am I. Lifelong layabout layman. EMAIL: baudell@ΑntіѕраΜgmail.com . Delete the “ΑntіѕраΜ” from my email address; it’s there in order to avoid spam. Also, I post at peirce-l and currently am co-manager there and co-manager & webmaster at Arisbe: The Peirce Gateway. I'm not Tetrast in Greece or on Twitter or art websites.
Links:
• Arisbe: The Peirce Gateway
• Peirce Dict.
• The Peirce Blog
• Peirce Matters
• Century Dict.
• Perseus-Tufts
• Math Atlas
• Math Subjects Classification
• Wolfram MathWorld
• Paul Burgess
Wikipedia hobby:
Did much editing on:
• Charles Sanders Peirce [as of 2022-12-9]
• CSP bibliography
• CSP's categories
• CSP's semiotic elements & classes of signs
• CSP's classification of the sciences
• Scientific method: Pragmatic model [mostly removed 2024-1-10]
• Charles Santiago Sanders Peirce

Deduction, induction, abduction, defined by logical-consequence relations.
Latest substantive edit: May 25, 2026. More edits to come.
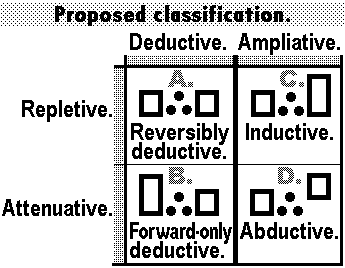
Square of proposed inference modes
from Table 1 below.
The definitions of deduction, induction, and abduction are rendered uniformly unambiguous by wielding the idea of logical consequence (positive, negated, inverse, etc.) to reframe induction and abduction. The definitions of induction and abduction emerge somewhat altered also in denotation, arguably for the better. Heuristically alluring qualities also are rendered more systematic.
- Skip table of contents.
- [Opening.] Tables 1, 2.
- Two notes.
- Trade-offs. Table 3. List. Table 4.
- Systematic opposition between definitive form and distinctive heuristics….
Table 5. Table 6. - Sorting actual thoughts. Table 7.
- Let guesses seem guesses…. Table 8.
- Rules, cases, facts.
- Inferring a rule from particulars: abductive vs. inductive.
- Induction.
- Note on synonymoids.
- Abductive yet non-explanatory inference.
- “Reverse inferences”….
- Abductive inference and statistical syllogism.
- Fields that aim toward [various inference modes].
- Semantic discussion: “ampliative inference” ≡ “non-deductive inference”.
- Adjective choices.
- Made-up names. Table 9.
- Appendix: long quotes from C. S. Peirce’s 1898–91 Century Dictionary definitions of:
ampliation (3.);
ampliative;
inference;
induction (5.);
hypothesis (4.);
and, from Hibbert Journal, Peirce’s 1908 discussion of
simpler hypothesis.
"Table of contents.

Deduction in logic is inference in which the premises (when conjoined) already make—in some form—the claim made by the conclusion. Hence, if the deduction’s premises are true, then its conclusion must be true, regardless of appearances to the non-omniscient reasoner. The conclusion is a logical consequence of the premises (i.e., semantically preserves truth of, or syntactically is entailed by, the premises).
Many seem to regard induction in logic as the only mode of non‑deductive inference or, at least, as the only one worthwhile. Starting with C. S. Peirce (1839–1914), some have, instead, divided non-deductive inference,— known since Peirce as ampliative inference,—into two modes: induction (≋ estimative generalization) and abduction (≋ surmise, explanatory guess);—and have not defined the two modes distinctly from each other in respect of logical-consequence relations;—yet have argued, cogently, for the distinct modes’ reality. An inductive-vs.-abductive distinction built of simple logical-consequence relations could bring some extra light to the theater of inference,—for plausible example, to automations of ampliative reasoning.
Trial can be started, at least. Divide all inference, deductive and ampliative alike, crosswise into two more modes, just as simple, that I call:
repletive (re-PLEE-tiv) inference,—in which the conclusion omits no claim made (in some form) by the premises;—hence, if the premises (as conjoined) are false, then the conclusion must be false; and
attenuative (a-TEN-yoo-ay-tiv)
inference,—in which the conclusion omits at least one claim made (in some form) by its premises;—hence, if the premises (as conjoined) are false, then still the conclusion doesn’t have to be false.
I first discussed adopting the words “repletive” and “attenuative” as terms in a post “Inference terminology” to peirce-l 2015-04-07. (Under “Adjective choices” far below, I discuss why the words seem better choices than others.)
| You walk; therefore, you walk. p ∴ p. Another example: pq ∴ qp. Deductive-cum-repletive inference ≡ reversible, equative deduction. Or call it equiduction. You walk & I talk; therefore, you walk. pq ∴ p. Another example: pqr ∴ pr. Deductive-cum-attenuative inference ≡ forward-only deduction. Or call it minuduction. |
You walk; therefore, you walk & I talk. p ∴ pq. Another example: pq ∴ pqr. Ampliative-cum-repletive inference, proposed as induction. Or call it pluduction. You walk; therefore, I talk. p ∴ q. Another example: pq ∴ qr. Ampliative-cum-attenuative inference, proposed as abduction. Or call it alduction. |
For each of the above inference modes, the proposed definition is clear-cut and, at most, only minimally procedural or algorithmic in content.
Nicely enough, most of the inferences classed by Peirce as (1) inductive or (2) abductive will remain so classed if,—pace tradition,—we define (1) induction as both repletive (its conclusion logically following from its premises) and ampliative;—and (2) abduction as both attenuative (its conclusion not logically following from its premises) and ampliative. (I made up some easy alternate names for the redefined modes in case some would prefer.)
Under those definitions, it remains classed as abductive to affirm (hypothetically as conclusion) the consequent that Socrates is (plausibly) a man, from the antecedents affirmed (categorically as premises) that Socrates is mortal and that all men are mortal. Meanwhile, inference from an existential particular proposition to the corresponding existential universal proposition remains classed as inductive (e.g., casually speaking: “Some food is good; therefore, some-and-all food is good.”).
On the other hand, inference of a Boolean hypothetical universal proposition, such as a law of nature (“inertia equals gravitational mass”), from some corresponding existential particular proposition(s), in a populous enough universe of discourse, becomes classed as abductive, rather than remaining classed as inductive. That is an improvement.
To abductively infer is traditionally supposed, since Peirce, to be to surmise, to inferringly guess or conjecture. To infer a rule from particulars (indeed from concrete individual facts) is to jump with both feet from affirming some instances into conjecturing an absence of counter-instances. It is not to generalize inductively from results of tests of said conjecture or hypothesis from a smaller to a larger positive population soever vast. More generally, it is not to inductively generalize an intermediate or other percentage or the like from part to larger positive whole deductively implying said part’s existence and pertinent character. Even Peirce classed inference of a rule from particulars as abductive at least once, in 1903 (see Essential Peirce 2, p. 287, both 1st and 2nd paragraphs). Richard Feynman said, to brief laughter during his “Seeking New Laws” lecture of 1964-11-19: “First, we guess it.”
I’ll focus hardly at all on the confirmatory and disconfirmatory means and roles of the basic inference modes; I agree that they include the key (as per Feynman) to science but I think that I’ve next to nothing unfamilar to say of them.
Systematic definitions and systematic heuristics. As a further nice result, all the modes of inference discussed here, deductive and non-deductive alike, when defined by properties belonging to logical consequence and logical non-consequence, become cleanly separated, classificationally, from distinctive heuristic properties which are needed together with the logical-consequence properties in order to make inference worthwhile at all. As correlatives to the main tetrachotomy’s inference modes, there come into clearer focus four heuristic properties which are usually attractive but, at best, variably reliable, usually familiar enough but seldom if ever recognized together as a family, and, among which, there is one that has been invoked by some to help define abduction. The four symmetrically patterned heuristic properties strikingly oppose and counterbalance,—one to one,—the four also symmetrically patterned limitations definitionally embedded,—one to one,—in the main tetrachotomy’s inference modes, which are the four most basic and least complicated overlaps of the four simplest modes (deductive, ampliative, repletive, attenuative) of inference, as defined above. Despite (or because of?) their practical tenor, the heuristic properties themselves have long seemed hard to quantify usefully or define precisely, to wit:
▰ an abductive conclusion’s (superlative or comparative or uncompared) plausibility, as natural simplicity in Peirce’s sense of naturalness of explanation, as by Galileo’s natural light of reason—an unnumerical semblance of such optimal or feasible cases as are numerically determinable by applying graph theory, Morse theory (extrema & critical points), relations of many to many;
▰ an inductive conclusion’s (non-Fisher) likelihood a.k.a. verisimilitude, in Peirce’s sense of similarity to the premises—an unnumerical semblance of such probability as is numerically determinable by applying counting, measure, relations of one to many (a.k.a. multi-value functions);
▰ a forward-only deduction’s conclusion’s aspect of newness, dissimilarity, to the premises—an unnumerical semblance of such information, news, as is numerically determinable by applying abstract algebra, many-to-one functions; and
▰ a reversible deduction’s conclusion’s nontrivialness or depth—an unnumerical semblance of such facts, data, contingent or so treated, more-or-less ordered, monadic or polyadic, as are numerically determinable by applying maths of order, ideal limits, bijections, one-to-one correspondences.
Some more things related to the proposed definitions and classifications are summarized in Table 2 below.
| Inference modes. | Deduction = non-ampliative inference. Premises logically lead to the conclusion or more. |
Ampliative inference = non-deductive inference Premises don’t logically lead to the full conclusion. |
|---|---|---|
| Proposed name: Repletive inference = non-attenuative inference. • Negative of the (conjoined) premises logically leads to negative of the conclusion. • Conclusion logically leads to the premises or more. |
A.  Repletive-&-deductive: Reversible deduction (i.e., through equivalence). — Counterbalancingly, its conclusions gain worth by nontrivialness, depth, complexity (from corollarial to theorematic). ☀ Reversible deduction is the typical mode of inferences via PURE MATHS: (1) many-to-many relations, topology, graph theory; (2) one-to-many relations, measure, counting; (3) many-to-one functions, abstract algebra; (4) bijective functions, ideal limits, order; The division into analysis & discrete maths seems to involve another dimension of classification. |
C.  By proposed definition as By proposed definition as Repletive-&-ampliative: Induction from part to whole that logically implies the part. — Counterbalancingly, its conclusions gain worth by verisimilitude, likelihood (in Peirce’s (non-Fisher) sense: similarity of conclusion to premises). ☀ Induction is the typical mode of inferences via STUDIES OF POSITIVE PHENOMENA IN GENERAL: (1) inverse optimization, allied descriptive studies; (2) statistics; (3) communication & control, incl. cybernetics; (4) some? of philosophy; |
| Proposed name: Attenuative inference = non-repletive inference. • Negative of the (conjoined) premises doesn’t logically lead to negative of the conclusion. • Conclusion doesn’t logically lead to the full premises. |
B.  Attenuative-&-deductive: Forward-only deduction. — Counterbalancingly, its conclusions gain worth by newness of aspect, dissimilarity to premises. ☀ Forward-only deduction is the typical mode of inferences via MATHS OF STRUCTURES OF ALTERNATIVES IN TIMELIKE PERSPECTIVES: (1) optima & feasible cases; (2) probabilities; (3) information, news; (4) contingent facts, data (maths of logic); |
D.  By proposed definition as
By proposed definition as Attenuative-&-ampliative: Surmise, conjecture, abductive inference. — Counterbalancingly, its conclusions gain worth by plausibility à la Peirce: instinctual simplicity & naturalness. ☀ Abductive inference is the typical mode of inferences via SCIENCES / STUDIES OF CONCRETE INDIVIDUAL PHENOMENA of: (1) motion; (2) matter; (3) life; (4) mind; |


Sanders Peirce
1839–1914
▼
Mathematician, logician, statistician, philosopher, scientist, and founder of the study of abductive inference
Two notes.
1. Note on terms. By standard definitions, all and only non‑deductive inference is ampliative inference, concluding in something extra in the sense of its not following purely from the premises. As said above, many use the term “induction” seemingly to refer to a one and only non-deductive mode of inference. (Mathematical induction, often called induction for short by mathematicians, is deductive, not also inductive except by an old definition.) In his classification of inferences, the logician and polymath C. S. Peirce typically asserted, throughout his adult life as a logician, a trichotomy of deduction, induction, and (under various labels) abduction, and called non‑deductive inference ampliative; Kant called non‑deductive judgement ampliative as well as synthetic, the latter in his famous analytic-synthetifc division of judgements. (Still, not every deductive judgement is a Kantian analytic judgement, since some deductive judgements are too manifestly redundant to count as explicative,—i.e., explicitative,—which any analytic judgement is supposed to be. The problem seems minimal until one extends the distinction to inferences.) See “Semantic discussion” far below. End of note.
2. Note on abductive inference. Abduction by my proposed (and seemingly original) definition is both ampliative and attenuative in both directions (between the premises as conjoined and the conclusion), ergo abductive in both directions, yet still tends to be retroductive, inferring a cause, reason, explanation, in only one direction. See more below under “Inferring a rule from particulars: abductive vs. inductive”. End of note.
Trade-offs.
| Inference Mode & Elementary Forms. | Model-Theoretically. | Proof-Theoretically. | Further Descriptions. |
|---|---|---|---|
| Deductive, e.g.: p ∴ p. pq ∴ p. | (Automatically) preserves truth. | • The premises entail the conclusion. • Denial of the conclusion entails denial of the premises. | The conclusion— is no stronger than, doesn’t exceed, doesn’t go beyond— the premises. |
| Ampliative, e.g.: p ∴ q. p ∴ pq. | Doesn’t (automatically) preserve truth. | • The premises don’t entail the conclusion. • Denial of the conclusion doesn’t entail denial of the premises. | The conclusion— is stronger than, exceeds, goes beyond— the premises. |
| Repletive, e.g.: p ∴ p. p ∴ pq. | (Automatically) preserves falsity. | • Denial of the premises entails denial of the conclusion. • The premises are entailed by the conclusion. | The premises— are no stronger than, don’t exceed, don’t go beyond— the conclusion. |
| Attenuative, e.g.: p ∴ q. pq ∴ p. | Doesn’t (automatically) preserve falsity. | • Denial of the premises doesn’t entail denial of the conclusion. • The premises aren’t entailed by the conclusion. | The premises— are stronger than, exceed, go beyond— the conclusion. |
Each of the four simplest modes of inference (the four in Table 3 just above) has its merits or virtues, as well as drawbacks or vices, in regard to the prospect of concluding in a truth or a falsehood:
- List: Security (futility) vs. opportunity (risk)
- Deductive inference does not decrease security / futility — i.e., does not increase opportunity / risk.
- Ampliative inference decreases security / futility — i.e., increases opportunity / risk — in some way.
- Repletive inference does not increase security / futility — i.e., does not decrease opportunity / risk.
- Attenuative inference increases security / futility — i.e., decreases opportunity / risk — in some way.
as prospects seen APART from their being counterbalanced in some sense by heuristic perspectives (such as plausibility or nontriviality) given by conclusions to premises.
I use the phrase “in some way” twice, in the bulleted list just above, in order to allude to the fact that an inference can be both ampliative and attenuative, i.e., it can at one same time increase risk (or whatever) in some way and decrease it in some other way. (Of course elementary inference, as a topic, does not exhaust the topic of security, opportunity, etc., and their increase and interplay in inquiry generally. Even at an elementary level, the prospects (of truth and falsehood) can be counterbalanced in some sense by heuristic perspectives given by conclusions to premises.)
Each merit or virtue among those built into the four simplest inference modes comes with a flipside drawback or vice. Risk managers sometimes say, “opportunity equals risk,” and call them two sides of the same coin. In that spirit: security, safeness, equals futility — “nothing ventured, nothing gained.” Freud made much from the titanic fact that one tends to have less choice between pleasure and pain than between both and neither. Each of the four simple modes of inference (those in Table 3 and in the bulleted list above here) works as a trade-off. On classical assumptions of two-valued logic, four mutually exclusive intersections of the above trade-offs, the above inference modes, necessarily arise and encompass all inferences:
| Inference modes | ⯆ ⯆ Deductive: NO INCREASE of opportunity / risk. |
⯆ ⯆ Ampliative ( = non-deductive): SOME INCREASE of opportunity / risk. |
|---|---|---|
|
Repletive: ⯈⯈
NO DECREASE of opportunity / risk. |
A. Reversible (i.e., equative) deduction. Repletive-&-deductive: NO decrease, NO increase, of opportunity / risk. |
C. Induction.
By proposed definition as: Repletive-&-ampliative: NO decrease, SOME increase, of opportunity / risk. |
|
Attenuative ⯈⯈
SOME DECREASE of opportunity / risk.( = non-repletive): |
B. Forward-only deduction. Attenuative-&-deductive: SOME decrease, NO increase, of opportunity / risk. |
D. Surmise, conjecture, abductive inference.
By proposed definition as: Attenuative-&-ampliative: SOME decrease, SOME increase, in different ways, of opportunity / risk. |
Peirce argued that every thought has the form of inference, and that, to see this, one needs to classify every thought correctly;—and Peirce offered as a complete basic classification a trichotomy of inference: abductive, inductive, deductive. Such completeness of a broadest polychotomy of inference modes can be secured more clearly by defining all the inference modes in question by logical-consequence relations in the obvious determinations (as the Scholastics might have called them): positive, negative, inverse, inverse of negative, not to mention their overlaps. Any unilingual grab-bag of univocal propositions (or, more generally, terms, e.g., in calculations), no matter how one divides said bag’s contents into bag of conjoined premises and bag of conjoined conclusions, belongs to exactly two of the above four simple modes (deductive, ampliative, repletive, attenuative) of inference, and to exactly one of their four overlaps. If, as Peirce argued, all thought is inference amd indeed inference valid in some sense, then—what makes an inference worthwhile is something more than justification, trueness of the premises, and the like.
• Some deductive conclusions, despite true premises and conformity to standard definitions of deduction, will be just too obvious, blatantly redundant, which is worthwhile and needful in elementary rules of deduction but seldom elsewhere as far as I know. Deductive validity and soundness do not ensure a conclusion worthwhile for a non-obvious — new or nontrivial — aspect that it gives to its premises.
• ANALOGOUSLY, some ampliative conclusions, despite true premises and conformity to standard definitions of ampliative inference, will be arbitrary and capricious: all too complicated and implausible, or all too novel and unlikely.
Diverse special forms are usually developed in order to help practitioners reach worthwhile conclusions in correspondingly diverse major inference modes attended, as all of them are, by logically rooted risks and opportunities. Broad enough INVENTORY finds an encompassing orderly pattern of OPPOSITIONS between (A) definitive forms of major inference modes and (B) the modes’ distinctive heuristics. The definitive forms can occasion trade-offs whereby prospects for conclusions can be favorably re-balanced, so to speak, by the distinctive heuristics. (I doubt that I have anything unfamiliar to say about the main inference modes’ distinctive confirmatory & disconfirmatory means & roles.)
Systematic opposition between definitive form and distinctive heuristics of each of the main four mutually exclusive and jointly exhaustive modes of inference.

1959, M.C. Escher
Inferences may be worth classifying in the above exact and regular tetrachotomous manner because then four major inference modes will be defined in a uniform hard-core formal manner that exhausts the possibilities, by their basic entailmental structures (or preservativeness or otherwise of truth and of falsity); meanwhile their various attempted heuristic merits —
◆ abductive conclusion’s plausibility (natural simplicity, in C. S. Peirce’s sense),
◆ inductive conclusion’s verisimilitude / likelihood (in Peirce’s non-Fisher sense: resemblance of conclusion to premises),
◆ forward-only-deductive conclusion’s new aspect, and
◆ reversibly-deductive conclusion’s nontrivialness / depth
— can be treated as forming a systematic class of aspects of fruitfulness or promisingness of inference, with each of them related (as the compensatory opposite, in a sense) to its respective inference mode’s definitive internal entailment structure.
Those heuristic merits are difficult to quantify usefully or even to define exactly; yet, together with the entailment structures, they illuminingly form a regular system in which each heuristic merit helps to overcome, so to speak, the limitations of its inference mode’s definitive entailment structure. At any rate there is a fruitful tension between heuristic merit and entailment structure in each inference mode.
| Inferences | Deductive: | Ampliative: |
|---|---|---|
| Repletive: | A. Reversible deduction, e.g.: pq ∴ pq. Logically simple. Compensate with the nontrivial, complex, deep. |
C. Induction, e.g.: pq ∴ pqr. Adds new claim(s). Compensate with (non-Fisher) verisimilitude, likelihood (qua conclusion’s likeness to the old claims). |
| Attenuative: | B. Forward-only deduction, e.g.: pqr ∴ pq. Claims less, vaguer. Compensate with newness, by concision, of aspect. |
D. Abductive inference, e.g.: pq ∴ qr. Logically complicated. Compensate with natural simplicity (abductive plausibility). |
Notes about Table 5 above:
- Systematic oppositions hold along the diagonals.
- All the heuristic merits considered here are those of aspects that conclusions give to premises, not those of a path of extra steps from premises to conclusion. Such paths reflect choices among more than one way up the mountain or molehill. Bennett 1988 introduced a quantitative concept for which he borrowed the phrase logical depth; but, last I looked, some Gödelian incompleteness rule precludes a general way to prove that a given actual program’s running time is the shortest possible for reaching a given result. The Pythagorean theorem has very many proofs and is considered deep but not all its proofs are considered especially deep or very nontrivial, especially in the sense of “difficult” that is often enough (and understandably) allied to the idea of the nontrivial. Also see Cosma Shalizi on complexity measures (http link).
- (i) Natural simplicity and (ii) (Peircean, non-Fisher) verisimilitude / likelihood contribute, in variable degree, to inclining the reasoner to believe or suspect a conclusion, at least until it is disconfirmed,
while, in systematic and symmetrical contrast to them,
(iii) novelty and (iv) nontrivialness contribute, in variable degree, to inclining the reasoner to disbelieve or doubt a conclusion, at least until it becomes established.
Those things emerge along the deductive-ampliative axis, the strongest axis. The matter becomes more complex when one incorporates the risk-versus-doubt profile along the repletive-attenuative axis. This material needs work:
Table 6.Logically rooted decrease & increase of RISK versus
perspectivally courted increase & decrease of DOUBT.(A) Deductive conclusion
does not increase risk
YET can invite increase
of doubt.(B) Ampliative conclusion
increases risk
YET can invite sameness
or decrease of doubt.
(1) Repletive conclusion
does not decrease risk
YET can invite decrease
of doubt.
(2) Attenuative conclusion
decreases risk
YET can invite sameness
or increase of doubt.
(A1) Repletive-&-
deductive
conclusion can have
nontrivialness, depth.
(A2) Attenuative-&-
deductive
conclusion can have
newness of aspect.
(B1) Inductive (defined as
repletive-&-ampliative)
conclusion can have (non-Fisher)
verisimilitude, likelihood.
(B2) Abductive (defined as
attenuative-&-ampliative)
conclusion can have
natural simplicity.
The result seems to be that, generally, in deduction, depth/nontrivialness and aspectual newness can invite doubt, but aspectual newness moreso; and that, generally, in ampliative inference, verisimilitude and natural simplicity can invite lessening of doubt, but verisimilitude moreso. - Update 8/30/2025 and successive days; and again on 5/11/2026. Peirce defined “verisimilar” and “likely” synonymously as applicable, in no precise degree, to an inductive conclusion based on premises of the right kind, but insufficient, to prove a deductive probability for the conclusion. There is likewise to define “plausible” and “simple in the sense of natural” synonymously as applicable to an abductive conclusion based on premises of the right kind, but insufficient, to establish the deductive optimality (or at least worthwhile deductive feasibility) of the abduction’s conclusion. Next, one turns on a dime to define “new in aspect” and, likewise, “nontrivial” as applicable to a deductive conclusion based on premises, of the right kind, but too complete, precluding the conclusion from delivering any information (news) or confirming any data or contingent facts (monadic or polyadic instances). I ought to develop these ideas further with help from the repletive-attenuative dichotomy. Note that these ideas, and their oppositions, are those in Table 5 above, but seen from a somewhat more practical angle. I ought to have made the remarks in this update years ago. End of update.
Sorting actual thoughts.
Now, an inference actually arising in a course of thought does not always present itself clearly. Hence, one may consider its seeming heuristic merit (such as plausibility), or its seeming purpose (such as explanation), in order to help one decide what mode of inference it ought to be framed as instancing.
It may even seem that one can pair the four entailment-structured definitions one-to-one with four definitions in terms of heuristics and/or function. Yet, for example, deduction is not defined as explicative, making explicit the merely implicit, since an inference with the form “p∴p”, e.g., “all is well, ergo all is well”, is deductive but its conclusion extracts no new or nontrivial perspective from its premises. Furthermore and as already said, the heuristic merits themselves resist exact definition.
On the other hand, if no deduction were ever to make explicit the merely implicit, then no mind would bother with deductive reasoning. The heuristic merits deserve attention because, in the pervasive absence of all the heuristic merits, no mind would bother with any reasoning — explicit, consciously weighed inference — at all. Deduction, whether repletive or attenuative, would lose as much in general justification and rationale as induction and abductive inference would lose. Little in general would remain of inference, conscious or unconscious, mainly such activities as remembering, and free-associative supposing, which are degenerate inferences analogously as straight lines are degenerate conics.
| Inferences | Deductive: | Ampliative: |
|---|---|---|
| Repletive: | Reversible deduction, e.g.: … ∴ p, ∴ p, ∴ p, ∴ … . Fixated remembrance. |
Induction, e.g.: … ∴ p∨q, ∴ q, ∴ qr, ∴ … . Swelling expectation. |
| Attenuative: | Forward-only deduction, e.g.: … ∴ pq, ∴ q, ∴ q∨r, ∴ … . Dwindling notice. |
Abductive inference, e.g.: … ∴ p, ∴ q, ∴ r, ∴ … . Wild supposition. |

Source: ResearchGate
So, the proposed entailment-relational definitions of inductive and abductive inferences admit of pointless inferences. Yet this seeming problem may help solve a bigger problem. After all, the standard definitions of deduction admit of pointless inferences as well —a conclusion that merely parrots a premise, or a conclusion that vacuously asserts an undisguised tautology. Definitions of deduction would be just as slippery as those of induction and abductive inference if one were to try to define deduction generally in terms of purposive and heuristic properties rather than in terms of entailment relations (or, just as well, preservativeness and non-preservativeness of truth and falsity).
In the study of arguments, most of the theoretical interest will be in schemata and procedures that both (A) bring “blackboard validity” — conformity with the entailment-relational definition (and concomitant virtues) of the given inference mode — and also (B) ensure some modicum of the inference mode’s correlated mode of promise, such as natural simplicity (Peirce’s forms), a new aspect (the categorical syllogistic forms), etc. Together, such conformity and such promise relate inference modes to distinctive aims at explanation, prediction, etc.
Let guesses seem guesses; let the definition be definite.

Source: Academia.edu
Editor, director, now retired,
at the Peirce Edition Project.
But now that abduction is taken seriously, and so much attention has turned to its examination, we find that it is indeed a very slippery conception.
— Peirce scholar Nathan Houser in “The Scent of Truth” in Semiotica 153—1/4 (2005), 455–466.
An unslippery definition of abductive inference is reached naturally in the course of defining all the broadest inference modes in a hard-core way systematically via entailment relations (or, just as well, via truth/falsity-preservativeness), such that abductive inference is definable as both ampliative (not automatically preserving truth) and attenuative (not automatically preserving falsity) — the premises neither entail, nor are entailed by, the conclusion.

The very idea of inference across both-ways non-entailment evokes the notion of leaps or guesses dauntingly to one who thinks of logic as properly strict and formal. The idea of course daunted me. I thought that almost nobody would take it seriously. Yet, it seemed pregnantly plausible that Nature or the Logos or the like would indeed favor use of all four of the basic inferential forms that suggest themselves to a systematic thinker. Then I came to read, gratefully, Peirce on abductive inference. Peirce never outright defined it as involving both-ways non-entailment, but he did call it guessing, at least in later years. Still, the idea of guessing as a mode of inference dissatisfies quite a few even when they do read Peirce.
Yet, a guess — in the sense of a conjecture or surmise — is an inference insofar as it consists in acceptance of a proposition (or term), even if but tentatively, on the basis of some proposition(s) (or term(s)). Now, a guess ought to be at least somewhat a leap, out of a box so to speak, just as a deductive conclusion ought to be technically redundant, staying in a box. They are simply different trade-offs between opportunity and security and, by the same stroke, between risk and futility.
Ergo, with all the company of logic and philosophy, without too much audācia, let guessing seem guessing. Let the definition of abductive inference PLAINLY represent the potential wildness of abductive conclusions, ANALOGOUSLY as most definitions of deduction PLAINLY represent the technical redundancy and potential vacuity of deductive conclusions.
Let the potential wildness of abductive conclusions be seen as counterbalanced by the practice, discussed richly by Peirce and exemplifiable in various particular forms, of finding plausibility (natural simplicity), along with conceivably testable implications, analogously as the technical redundancy and potential vacuity of deductive conclusions are seen as counterbalanced by the practice, exemplifiable in various particular forms, of finding a new or nontrivial aspect, also conceivable further testability. Analogous remarks can be made about induction, Peircean verisimilitude / likelihood, and testability.

Source: Academia.edu
Thusly defined as both ampliative and attenuative, — and thusly distinguished as attenuative, from induction as repletive, — abductive inference would plainly gain the AUTONOMY found lacking by Tomis Kapitan (1949–2016) in “Peirce and the Autonomy of Abductive Reasoning” (PDF) in Erkenntnis 37 (1992), pages 1–26, an article discussed in Houser’s article linked above. (Kapitan also wrote “Abduction as Practical Inference”, published online in 2000 in the Digital Encyclopedia of Charles S. Peirce, reproduced at Commens.org.)
In other words, abductive inference would not boil down, in such analysis, to some application, practical or theoretical, of deduction and/or induction. Worthwhile, pertinent ideas about natural simplicity, explanatory power, pursuit-worthiness, etc., which contribute to the current slipperiness of definitions of abductive inference, would instead be further salient issues of abductive inference, neither explicitly contemplated in its definition nor axiomatized, postulated, or otherwise incorporated into the content of all abductive premises and conclusions. Such incorporation, besides the problems that Kapitan finds, would make one abductive conclusion into many conflicting ones, a continuum of potential conflicting ones, just by people’s differing soever fuzzily in the amounts of plausibility, economy, pursuit-worthiness, etc., that they claim in it. Define abductive inference BY its form, NOT BY its heuristics and functionality, just as with deduction, where the somewhat slippery but valuable and pertinent ideas of novelty, nontrivialness, predictive power, etc., are further salient issues of deduction, neither explicitly contemplated in its standard definitions nor incorporated into the content of all deductions (and such couldn’t usefully be done deductively). Such spartanism at the elementary level need not and ought not go so far as to forbid explicitly qualifying the illative relation by saying “therefore, abductively,” or “therefore, deductively,” or the like, which very arguably Peirce would have endorsed (but not strictly demanded).
Yet, some slipperiness remains, which the proposed definitions of the inference modes do not entirely remedy. I will take this up in the next subsection “inferring a rule from particulars”.
Rules, cases, facts.
Inferring a rule from particulars: abductive vs. inductive.
Given this post’s proposed definitions of induction and abduction, logically attenuative inference from one or more particulars to a rule is classed among abductive forms rather than inductive.
For example: “some fruit is sweet, therefore (rule) no fruit is not sweet (i.e., in logicians’ lingo, all fruit are sweet)”.
That fruit example concludes with a potentially very long shot from an existential particular to a (Boolean) hypothetical universal. The example does feel like a surmising, a conjecturing but, under the proposed definitions, we haven’t needed to guess its classification, since its classification is determined only by the overall relation of entailing and being entailed (or, just as well, truth/falsity preservativeness) between the premises as a whole and the conclusion as a whole.
Now, the original idea of induction was inference from particulars to a rule (see Peirce in the Century Dictionary below); but one typically assumed the rule to be an (Aristotelian) existential universal, such that “Every fruit is sweet” entails, deductively implies, its subaltern “Some fruit is sweet” (look up immediate inference). Even under the inference-mode definitions herein proposed, inference of an existential universal from (existential) particulars in a populous enough universe of discourse will, in some cases, be inductive, not abductive.
- In earlier years Peirce often portrayed abduction (calling it “hypothesis”) as inference from rule (all men are mortal) and fact (Socrates is mortal) to case (Socrates is a man), and as involving no generalization (see below for a quote from 1889–91). Later, Peirce at least once countenanced the abducing of rules from particulars. In his 1903 Syllabus of his Lowell lecture series Some Topics of Logic, he wrote (Essential Peirce 2, 287, in 1st paragraph, see at Commens):
The whole operation of reasoning begins with Abduction […]. Its occasion is a surprise. […]. The mind seeks to bring the facts, as modified by the new discovery, into order; that is, to form a general conception embracing them. In some cases, it does this by an act of generalization. In other cases, no new law is suggested, but only a peculiar state of facts that will “explain” the surprising phenomenon; and a law already known is recognized as applicable to the suggested hypothesis, so that the phenomenon, under that assumption, would not be surprising, but quite likely, or even would be a necessary result. […].
- One may wonder whether, in that passage, Peirce implicitly meant an INDUCTIVE generalization, not an abductive one, to a new law; but soon (in the 2nd paragraph on the same page 287 in EP 2, see at Google Books), Peirce wrote regarding deduction’s taking up an abduced hypothesis:
[…] either in the hypothesis itself, or in the pre-known truths brought to bear upon it, there must be a universal proposition, or Rule.
So, again, Peirce held at least in 1903 that a hypothesis abduced from particulars can contain a newly guessed rule.
Feynman asked, how do we find new laws? and emphasized that first, we guess them. Induction on the other hand, if defined as ampliative and repletive, seems oftenest concerned with estimating about one or another population or universe of discourse that requires not some universal quantification(s) “∀x ∀y Hxy” or the like that shoots its arrow through a hole in every axe at once, so to speak, but instead a collective predicate (such as the term “gamut”) attributing a distribution of properties, a relation, a percentage, etc., across that entire population or universe of discourse as one entire polyadic instance (at least implicitly), an ascription toward which an inductive inference seeks to expand the claims in its premises without squintingly narrowing its focus exclusively to rules up, up, and away from a variegated densely woven landscape.
Whew.
| Choose a postulate or axiom (i.e., a validity rule) that the universe of discourse contains exactly… 🢃 |
Next, suppose an inference:There is a horse;In the universe chosen via a given row’s heading, the above inference to a rule is: 🢃 |
Next, suppose an inference: There is something both a horse & magnificent;In the universe chosen via a given row’s heading, the above inference to a rule is: 🢃 |
| …zero objects. | Forward-only-deductive, but necessarily unsound. | Forward-only-deductive, but necessarily unsound. |
| …one object. | Reversibly deductive. | Forward-only-deductive. |
| …zero or one object. | Forward-only-deductive. | Forward-only-deductive. |
| …one or more objects. | Inductive. | Abductive. |
| …zero or more objects (the most general case). | Abductive. | Abductive. |
To make the abductive equine example somewhat more realistic, suppose that the inference is something more like: There exists planet Earth with quite various countries crowded on it, among most of which are known to be distributed all known horses, and every such horse is known to be magnificent. Therefore, all horses are magnificent.

Source: BBC video via Cornell U. via YouTube.
[…]. In general, we look for a new law by the following process.
First, we guess it. Then we com- — w- – don’t laugh, that’s the - really true. Then we compute the consequences of the guess, to see what, if this is right, if this law that we guessed is right, we see what it would imply and then we compare those computation results to nature or we say compare to experiment or experience, — compare it directly with observations to see if it, if it works.
If it disagrees with experiment, — it’s wrong. In that simple statement is the key to science. It doesn’t make a difference how beautiful your guess is, it doesn’t matter how smart you are, who made the guess, or what his name is. If it disagrees with experiment, it’s wrong. That’s all there is to it.
It’s therefore not unscientific to take a guess although many people who are not in science think it is. […].
— Richard Feynman, 11/19/1964, his Cornell U. Messenger Lecture series “The Character of Physical Law”, Lecture 7: “Seeking New Laws” (go to 16:29).
C. S. Peirce does at least once discuss a kind of abductive inference that concludes in a “generalization” to a new law (1903, see The Essential Peirce v. 2, p. 287, both paragraphs, see above). Peirce in earlier years described generalization as selective of the characters generalized (decreasing the comprehension while increasing the extension, see “Upon Logical Comprehension and Extension”, 1867, Collected Papers v. 2 ¶422, also in Writings v. 2, p. 84), and as casting out “sporadic” cases (“A Guess at the Riddle”, 1877–8 draft, see The Essential Peirce v. 1, p. 273). If, in the 1903 passage, he is discussing abductive inference by selective generalization quite generically, then any crude induction from the mass of experience seems to count as abductive instead.
Induction from sample to definite total population, as people actually frame it in practice, is sometimes not only ampliative but also attenuative — the conclusions do not always entail the premises, even though one usually thinks of induction as inferring from a part to a whole including the part.
There are ways to reframe the induction “half this [designated, indicated] actual sample is blue, so half the total is blue” so that its conclusion will entail its premise, ways that are perhaps to be favored over the example if they reflect better the inquirial interest involved in induction:
—one could say “some subset” or “some randomly drawn subset” (or the like) instead of “this actual sample” (or the like); or
—one could characterize this actual sample in the conclusion as well as in the premise (like a concluding graph that represents the actual measurements with a heavier line); or
—one could define a certain designated total population such that the definition is a kind of census explicitly designating each of the individuals in the population, and
—of course there are likely other ways that I haven’t thought of.

Source: Wikipedia
Such perspectives suit checking consistency by the deducibility of the premise from the conclusion and, beyond that, deducing what would be the probability of drawing a given subset as a sample given alternate possible parameters of the total population. Update: Indeed in statistics, since the polymath Ronald Fisher’s papers in 1921–2, such a probability is distinguished as a likelihood function or, for short, a likelihood (not in Peirce’s sense); likelihoods are compared across conflicting scenarios a.k.a. parameter sets a.k.a. universes of discourse and hence generally do not sum to 100%, which is an incentive not to call them probabilities.
Note on synonymoids.
I’d advise against usage of the English word “verisimilitude” in place of the English word “likelihood” in order to refer to Peirce’s idea of verisimilitude or likelihood unconfused with Fisher’s idea of likelihood—such a usage would invite mounting translational confusions; examine the onrushing list:
—1. (mathematical) “probability”,— 2. “likelihood” (in Fisher’s sense),
are translated:
—1. Wahrscheinlichkeit,—2. likelihood, in German;
—1. probabilidad,—2. verosimilitud, in Spanish;
—1. probabilidade,—2. verossimilhança, in Portuguese;
—1. probabilità,—2. verosimiglianza, in Italian;
—1. probabilité,—2. vraisemblance, in French.
Note that the German word Wahrscheinlichkeit for (mathematical) probability is etymologically quite analogous to English “verisimilitude”. In still other languages, the word for verisimilitude (in Fisher’s sense) is one or another word for plausibility.
Meanwhile the English word “verisimilitude” is nowadays used by at least some philosophers to mean completeness of representation, and they contrast it with some sort of subjective probability. One could double down on verbal tangles and start using the variant word “likeliness” distinctively to mean Peircean heuristic likelihood / verisimilitude. I instead suggest a distinctive new set of words for that and other heuristic characteristics of conclusions, below under “Made-up names”. End of note.
Abductive yet non-explanatory inference.
If one re-defines abduction (as in this discussion) as inference in which the premises do not entail the conclusion and in which the conclusion does not entail the premises, then the inference is abductive both forwards, from premises to conclusion, and backwards, from conclusion to premises. One soon sees the difficulty of characterizing such inference as typically explanatory both forwards and backwards; instead one abductively infers from given consequences to ungiven reasons. (This asymmetry is actually another improvement;—it brings abductive inference, with its reversible non-entailment structure, into contextual unidirectionality, but in the direction opposite to that of reversibly deductive proof of a thesis through equivalences from given reasons to ungiven consequences.)
Now, take a famous example of abductive inference:
The lawn is wet this morning.
Whenever it rains at night, the lawn is wet the next morning.
Therefore [hypothetically] it rained last night.
Now, suppose that the example of abductive inference is instead:
It rained last night.
Whenever the lawn is wet in the morning, it has rained the previous night.
Therefore [hypothetically] the lawn is wet this morning.
That is not a usual abductive inference to a cause or reason, because it is hard to see how the hypothesized circumstance that the lawn is wet this morning would explain the fact that it rained last night.
Rather than try to see every individual effect in an individualized teleological light, it is simpler to note that abductive inference (in the sense of inference both ampliative and attenuative) can go in either direction between its set of premises and its set of conclusions, likewise as reversible deduction can. This view does not vitiate the connection between abductive inference and explanation, and this is likewise as the analogous view about reversible deduction does not vitiate the connection between reversible deduction and proving a theorem or corollary.
Just as mathematical reversible deduction has a preferred direction given as its purpose of moving from things already postulated or proven (i.e., moving FROM reasons) to conclusions new to the non-omniscient reasoner, so likewise abductive inference in the sciences of concrete phenomena has a preferred direction by its purpose of moving from effects to causes (i.e., moving TOWARD reasons). Thus BOTH abductive inference and reversible deduction can be BOTH (A) defined in terms of entailment (or truth/falsity preservativeness) and (B) characterized by their respective purposes. It’s a GOOD thing.
Mathematicians often enough move in the reverse direction in their “scratch work”, from thesis that needs proof, to something already postulated or proven — then, if every step has been through a deductive equivalence, they can simply reverse the order of the scratch work to produce the proof. Mobility in both directions seems less dazzling in abductive inference, at least insofar as abductive inferences (and non-mathematical inferences generally as Zadeh mentioned somewhere) tend to be less lengthy than reversible deductions which can become very long chains.
“Reverse inferences”: abduction vs. induction vs. deduction.
Abduction can seem deduction in reverse, e.g., using Peirce’s terms rule, case, and fact:
Deduction:
Rule: All food tastes good.
Case: This fish is food.
Therefore, deductively,
Fact: This fish tastes good.Abduction:
Fact [oddly]: This fish tastes good.
Rule: All food tastes good.
Therefore, abductively,
Case [plausibly]: this fish is food.
Yet the reversed Barbara deduction is not the abductive syllogism above. Instead, it is the capricious:
Fact: This fish tastes good.
Therefore: Case: This fish is food; and Rule: All food tastes good.
—which is both ampliative and repletive (i.e., inductive, not abductive, under present text’s proposal).
Also, the reversed traditional abductive syllogism is the capricious:
Case: This fish is food.
Therefore: Fact: This fish tastes good; and Rule: All food tastes good.
However, suppose that one makes not just a premise but a postulate (or axiom) of the rule that all food tastes good. Then the rule will remain among the premises when the case and the fact switch places between the premise set and the conclusion. Under the postulate that all food tastes good:
• from the fact that this fish tastes good, one becomes able to induce to the case that this fish is food; and
• from the case that this fish is food, one becomes able to (attenuatively) deduce the fact that this fish tastes good.
So, as a result of the proposed definitions of induction and abduction:
• an inference will be abductive if it extends an unpostulated rule to cover something as a case to explain a fact, and will not be the reverse of deduction of same fact from rule and case; and, by the same stroke,
• if the rule has been postulated, then the aforesaid inference will be inductive and its reverse will be deductive (& attenuative).
Abductive inference and statistical syllogism.
“It has rained every day for a week. Therefore tomorrow it will rain.” Thusly framed, that inference is both ampliative and attenuative, hence abductive under the proposed definition. But it is just as natural to frame the thought as being, that it has rained every day for a week and that therefore tomorrow it will again rain, rain for the eighth consecutive day, etc., at which point the inference is framed as inductive; that seems much of its spirit. It turns into a kind of statistical syllogism, that is, a statistical induction concluding in a premise for an attenuative deduction — in this case, an induction from seven consecutive rainy days as of today to eight consecutive rainy days as of tomorrow, followed by an attenuative deduction (from the eight consecutive rainy days as of tomorrow) to a rainy day tomorrow, full stop. The restatement does justice to both the expansion, and the subsequent contraction, of focus of the original inference, by framing them separately in component inferences. When an inference, seemingly in a given mode, is so easily analyzed, reduced, into worthwhile component inferences in other modes, then it seems fair enough, if not fairer, to regard it as basically such a composition.
Fields that aim toward: reversible deduction; forward-only deduction; induction; and abductive inference.

Source: Herald-Tribune
The highest order of the imaginative intellect is always pre-eminently mathematical, or analytical; and the converse of this proposition is equally true.
— E. A. Poe, “American Poetry”, 1845, first paragraph, link to text.

Source:
Municipality of Aristotle
Reciprocation of premises and conclusion is more frequent in mathematics, because mathematics takes definitions, but never an accident, for its premises — a second characteristic distinguishing mathematical reasoning from dialectical disputations.
— Aristotle, Posterior Analytics, Bk. 1, Ch. 12, link to text.
Pure mathematics is marked by far-reaching networks of bridges of equivalences between sometimes the most disparate-seeming things. With good reason, popularizations often focus on examples of the metamorphosic power of mathematics. A topologist once told me that the statement “These two statements are equivalent” is itself one of the most common statements in mathematics. In a mundane example of a bridge by equivalence, in mathematical induction (actually a kind of deduction), one takes a thesis that is to be proved, and transforms it (in a fairly simple step) into the ancestral case and the heredity, conjoined. Once they’ve been separately proved (such is the hard part, also, I’ve read, often done by deductions through equivalences), then the mathematical induction itself, the induction step, consists in transforming (again, in a simple step) the conjunction of ancestral case with heredity back into the thesis, demonstrating the thesis. The reasoning in pure mathematics tends to be transformative, from one proposition (or compound) to another proposition equivalent to it and already proved or postulated or just easier or more promising to work with for the purpose at hand. When one’s scratch work proceeds through equivalences from a thesis to postulates or established theorems, then one can simply reverse the order of the scratch work for the proof of the thesis. Reverse mathematics, a project born in mathematical logic, takes up the question of just which mathematical theorems entail which sets of postulates as premises. This shows again the prominence of deduction through equivalences in pure mathematics. The reverse of the reasoning in pure mathematics is typically still reasoning by pure mathematics (even if with inquisitive guidance from mathematical logic).

Source: Columbia U
In an example contrasting to that, deduction of probabilities and statistical induction, two neighborly forms of quite different modes of inference, are seen as each other’s reverse or inverse, deduction of probabilities inferring (through forward-only deduction) from a total population’s parameters to particular cases, and statistical induction inferring in the opposite direction (e.g., in Jay L. Devore’s Probability and Statistics for Engineering and the Sciences, 8th Edition, 2011, beginning around “inverse manner” on page 5, into page 6). Such deductive fields as probability theory seem to involve the development of applications of pure mathematics in order to address “forward problems” in general: the problems of deducing solutions, predicting data, etc. from the given parameters of a universe of discourse, a total population, etc., with special attention to structures of alternatives and of implications. That description fits the deductive mathematics of optimization, probability (and uncertainty in Zadeh’s sense), and information (including algebra of information), and at least some of mathematical logic.
Now, statistical probability should not be nicknamed “inverse probability”, an obsolete phrase that comes from DeMorgan’s discussion of LaPlace and refers to a more specific idea, involving the method of Bayesian probability. On the other hand, the inverse of mathematics of optimization actually goes by such names as inverse optimization and inverse variations. On a third hand, inverse problem theory seems to concern inferring from observed effects to unobserved causes governed by known rules, and this seems a kind of abductive inference, albeit with a special emphasis on knowing the governing rules pretty comprehensively.
It is in the (comparatively) concrete sciences, the sciences of motion, matter, life, and mind, that abductive inference takes center stage. I’ll add some discussion here later.
Semantic discussion: “ampliative inference” ≡ “non-deductive inference”.
Question: does the phrase “ampliative inference” mean
• simply non-deductive inference (as I’ve taken it to mean) or, instead,
• inference that both (A) is non-deductive and (B) entails all its premises in its conclusion?
Peirce’s examples of abductive reasoning had premises that were not only far from entailing their conclusions, but also far (too far for a fair reframing to close the gap) from being entailed by their conclusions. He often classified abductive inference (which he also called hypothesis, retroduction, and presumption) as ampliative. Hence it is safe to say that his “ampliative” inference meant simply the non-deductive, not the both repletive and non-deductive. This was both (A) during the years that he treated abductive inference as based on sampling and as a rearrangement of the Barbara syllogism, and (B) afterwards, in the 1900s.
⯈ 1883:
We are thus led to divide all probable reasoning into deductive and ampliative, and further to divide ampliative reasoning into induction and hypothesis. [….]
—Page 143 in “A Theory of Probable Inference” in Studies in Logic. ⯇
⯈ 1889–91 Century Dictionary (“CD”), first edition: Peirce’s definition of “ampliative” (see below) says that it and “explicative” are alternates for the translative words “synthetic” and “analytic” in Kantian philosophy. Peirce also sets “explicative inference” and “ampliative inference” as “opposite” to each other in his bountiful definition of inference (see below) in CD. Note that explicative inference amounts to deduction of a not fully obvious conclusion; it doesn’t merely parrot one or more premises:
[….] Explicative inference, an inference which consists in the observation of new relations between the parts of a mental diagram (see above) constructed without addition to the facts contained in the premises. It infers no more than is strictly involved in the facts contained in the premises, which it thus unfolds or explicates. This is the opposite of ampliative inference, in which, in endeavoring to frame a representation, not merely of the facts contained in the premises, but also of the way in which they have come to present themselves, we are led to add to the facts directly observed. [….]
What may remain unclear to a reader of that passage is whether no ampliative conclusion omits a claim from its premises. Yet, if ampliative inference includes abductive inference (a.k.a. hypothesis), then an ampliative conclusion certainly can omit claims from the premises and remain ampliative, as one can see from Peirce’s many examples.
Meanwhile, the line between non-explicative and explicative deduction, i.e., between obvious and non-obvious deduction, seems not perfectly clear.
Also, the ampliative-deductive division is a dichotomy of all inferences. Explicative inferences, as forming a proper subset of deductions, are better opposed to an analogous proper subset of ampliative inferences, a proper subset consisting of ampliative inferences of which each conclusion accepts at least some definite matter from its premises, rather than veering whole-hog arbitrarily into an unrelated matter. This somewhat oversimplifies, but: Non‑explicative deductions parrot too much while, toward an opposite extreme, capricious ampliative inferences parrot too little.
• Kant’s analytic judgments = explicative conclusions = some deductive conclusions, but not the blatantly redundant ones, rather those that give a new or nontrivial aspect to their premises.
• Kant’s synthetic judgments = ampliative conclusions, from mild to wild, from likely or plausible to unlikely and implausible.
Anyway, like most who contemplate inference modes, Peirce usually refers to deductive (rather than explicative) inference in discussing inference in mathematics, traditional categorical syllogisms, and mathematical probabilities. ⯇
⯈ 1892: Peirce treats “non-deductive” and “ampliative” as alternate labels for the same kinds of inference, as follows in “The Doctrine of Necessity Examined”, § II, 2nd paragraph:
[….] Non-deductive or ampliative inference is of three kinds: induction, hypothesis, and analogy. If there be any other modes, they must be extremely unusual and highly complicated, and may be assumed with little doubt to be of the same nature as those enumerated. For induction, hypothesis, and analogy, as far as their ampliative character goes, that is, so far as they conclude something not implied in the premises, depend upon one principle and involve the same procedure. All are essentially inferences from sampling. [….]
(Throughout the years, he usually regarded analogy as a combination of induction and hypothetical inference.) ⯇
⯈ 1900s: Peirce ceased holding that hypothetical (a.k.a. abductive, a.k.a. retroductive) inference aims at a likely conclusion from parts considered as samples, and argued instead that abductive inference aims at a plausible, natural, instinctually simple explanation as (provisional) conclusion and that it introduces an idea new to the given case, while induction merely extends to a larger whole of cases an idea already in the abduction’s conclusion, an idea that is then asserted in the induction’s premises. ⯇
⯈ 1902: In a draft, regarding his past treatment of abductive inference, Peirce wrote,
I was too much taken up in considering syllogistic forms and the doctrine of logical extension and comprehension, both of which I made more fundamental than they really are.
— Collected Papers v. 2, ¶ 102. ⯇
Adjective choices.
“Repletive” (re-PLEE-tiv) seems a better adjective than “retentive” for non-attenuative inference (although maybe it’s just me), because “retentive” suggests not just keeping the premises, but restraining them or the conclusions in one sense or another. The word “preservative”, to convey the idea of preserving the premises into the conclusions, would lead to confusion with the more usual use of “preservative” in logic’s context to pertain to truth-preservativeness (not to mention falsity-preservativeness).
“Attenuative” (a-TEN-yoo-ay-tiv) seems much better than “precisive” or “reductive” for non-repletive inference. The adjective “precisive” seems applicable only abstrusely to an apparently dis-precisive inference in the form of “p, therefore p or q”. Attenuative inference generally narrows logical focus, but in doing this it renders vague (i.e., omits) some of that which had been in focus. “Reductive” may be less bad than “precisive” in those respects but is rendered too slippery by irrelevant senses clinging from other contexts and debates.
Made-up names.
| Inferences | Deduction: | Ampliative inference, or ampliduction: |
|---|---|---|
| Repletive inference, or replenduction: |
A. Equiduction (ē-kwi-duk′ -sho̤n) ≡ reversible deduction. Conclusion tries to be prolentorous (prō-len′ -to̤-rus) (i.e., nontrivial, deep, complex, difficult) . |
C. Pluduction (plo͞o-duk′ -sho̤n) ≋ induction. Conclusion tries to be proveterous (prō-vet′ -e̤-rus) (i.e., verisimilar, likely, in Peirce’s non-Fisher sense. |
| Attenuative inference, or attenuduction: |
B. Minuduction (mīn-ụ̄-duk′ -sho̤n) ≡ forward-only deduction. Conclusion tries to be projuvenous (prō-jo͞o′- ve-nus) (i.e., new in aspect). |
D. Alduction (al-duk′ -sho̤n) ≋ abductive inference. Conclusion tries to be procelerous (prō-sel′ -e̤-rus) (i.e., instinctually simple, natural, facile, plausible à la Peirce). |

Provisional set of TERMS for
DICHOTOMIES OF inference modes.
◧ vs.◨ MAIN: deductive VS. ampliative.
⬒ vs.⬓ SECONDARY: repletive VS. attenuative.
▚ vs. ▞ TERTIARY: parductive VS. disparductive,
i.e., mode-preservatively reversible
VS. not mode-preservatively reversible.
APPENDIX: Charles Sanders Peirce’s definitions of ampliation 3. (in logic), ampliative, inference, induction 5. (in logic), and hypothesis 4., in 1889–91 in the Century Dictionary; and his discussion of simpler hypothesis in 1908 in Hibbert Journal.
Here are two excerpts from 1889–91 (and identically in 1911) from the Century Dictionary’s definitions of “ampliation” and “ampliative”, of which Peirce was in charge of the definitions, per the list of words compiled by the Peirce Edition Project’s former branch at the Université de Québec à Montréal (UQÁM).
ampliation (am-pli-ā′ sho̤n) […] — 3. In logic, such a modification of the verb of a proposition as makes the subject denote objects which without such modification it would not denote, especially things existing in the past and future. Thus, in the proposition, “Some man may be Antichrist,” the modal auxiliary may enlarges the breadth of man, and makes it apply to future men as well as to those who now exist.
ampliative (am′ pli-ạ̄-tiv) […] Enlarging; increasing; synthetic. Applied — (a) In logic, to a modal expression causing an ampliation (see ampliation, 3); thus, the word may in “Some man may be Antichrist” is an ampliative term. (b) In the Kantian philosophy, to a judgment whose predicate is not contained in the definition of the subject: more commonly termed by Kant a synthetic judgment. [“Ampliative judgment” in this sense is Archbishop Thomson’s translation of Kant’s word Erweiterungsurtheil, translated by Prof. Max Müller “expanding judgment.”]
No subject, perhaps, in modern speculation has excited an intenser interest or more vehement controversy than Kant’s famous distinction of analytic and synthetic judgments, or, as I think they might with far less of ambiguity be denominated, explicative and ampliative judgments. Sir W. Hamilton.
— Century Dictionary, p. 187, in Part 1: A – Appet., 1889–91, of Volume 1 of 6, first edition, and identically on p. 187 in Volume 1 of 12, 1911 edition. The brackets around the sentence mentioning Archbishop Thomson are in the originals.
Peirce for his own part focused on the deductiveness or ampliativeness of inference, not of ready-made judgments (he once said that a Kantian synthetic judgment is a “genuinely dyadic” judgment, see Collected Papers v. 1 ¶ 475). Peirce argued that mathematics aims at theorematic deductions that require experimentation with diagrams, a.k.a. schemata, and that it concerns purely hypothetical objects. (So much for Kant’s synthetic a priori.)
The following is from the first edition, 1889–91, CD volume 3, CD part 11 Ihleite – Juno, CD pages 3080–1. Peirce was in charge of the CD’s definition of inference, per the list of words compiled by the Peirce Edition Project’s former branch at the Université de Québec à Montréal (UQÁM). I recently typed the text out from the Internet Archive, so I’d suggest checking it against the Internet Archive version if you quote or copy from the resultant text below. Let me know if you find an error.
inference (in′ fėr-ens), n. [= F. inférence = Sp. Pg. inferencia, ˂ ML. inferentia, inference, ˂ L. inferre, infer: see infer.] 1. The formation of a belief or opinion, not as directly observed, but as constrained by observations made of other matters or by beliefs already adopted; the system of propositions or judgments connected together by such an act in a syllogism — namely, the premises, or the judgment or judgments which act as causes, and the conclusion, or the judgment which results as an effect; also, the belief so produced. The act of inference consists psychologically in constructing in the imagination a sort of diagram or skeleton image of the essentials of the state of things represented in the premises, in which, by mental manipulation and contemplation, relations that had not been noticed in constructing it are discovered. In this respect inference is analogous to experiment, where, in place of a diagram, a simplified state of things is used, and where the manipulation is real instead of mental. Unconscious inference is the determination of a cognition by previous cognitions without consciousness or voluntary control. The lowest kind of conscious inference is where a proposition is recognized as inferred, but without distinct apprehension of the premises from which is has been inferred. The next lowest is the simple consequence, where a belief is recognized as caused by another belief, according to some rule or psychical force, but where the nature of this rule or leading principle is not recognized, and it is in truth some observed fact embodied in a habit of inference. Such, for example, is the celebrated inference of Descartes, Cogito, ergo sum (‘I think, therefore I exist’). Higher forms of inference are the direct syllogism (see syllogism); apagogic inference, or the reductio ad absurdum, which involves the principle of contradiction; dilemmatic inference, which involves the principle of exluded middle; simple inferences turning upon relations; inferences of transposed quantity (see below); and the Fermatian inference (see Fermatian). Scientific inferences are either inductive or hypothetic. See induction, 5, and analogy, 3.
2. Reasoning from effect to cause; reasoning from signs; conjecture from premises or criteria; hypothesis.
An excellent discourse on . . . the inexpressible happiness and satisfaction of a holy life, with pertinent inferences to prepare us for death and a future state.
Evelyn, Diary, Nov. 21, 1703.He has made not only illogical inferences, but false statements.
Macaulay, Mitford’s Hist. Greece.Take, by contrast, the word inference, which I have been using: it may stand for the act of inferring, as I have used it; or for the connecting principle, or inferentia, between premises and conclusions; or for the conclusion itself.
J. H. Newman, Gram. of Assent, p. 254.Alternative inference. See alternative. — Ampliative inference. See explicative inference, below. — Analogical inference, the inference that a certain thing, which is known to possess a certain number of characters belonging to a limited number of objects or to one only, also possesses another character common to those objects. Such would be the inference that Mars is inhabited, owing to its general resemblance to the earth. Mill calls this inference from particulars to particulars, and makes it the basis of induction. — Apagogical inference, an inference reposing on the principle of contradiction, that A and not-A cannot be predicated of the same subject; the inference that a proposition is false because it leads to a false conclusion. Such is the example concerning mercury, under deductive inference, below. — Comparative inference. See comparative. — Complete inference, an inference whose leading principle involves no matter of fact over and above what is implied in the conception of reasoning or inference: opposed to incomplete inference, or enthymeme. Thus, if a little girl says to hereself, “It is naughty to do what mamma tells me not to do; but mamma tells me not to squint; therefore it is naughty to squint,” this is a complete inference; while if the first premise does not completely and explicitly appear in her thought, although really operative in leading her to the conclusion, it ceases to be properly a premise, and the inference is incomplete. — Correct inference, an inference which conforms to the rules of logic, whether the premises are true or not. — Deductive inference, inference from a general principle, or the application of a precept or maxim to a particular case recognized as coming under it: a phrase loosely applied to all explicative inference. Example: Mercury is a metal, and mercury is a liquid; hence, not all metals are solid. The general rule here is that all metals are solid, which is concluded to be false, because the necessary consequence that mercury would be solid is false. — Direct deductive inference, the simple inference from an antecedent to a consequent, in virtue of a belief in their connection as such. Example: All men die; Enoch and Elijah were men; therefore they must have died. — Disjunctive inference. Same as alternative inference. — Explicative inference, an inference which consists in the observation of new relations between the parts of a mental diagram (see above) constructed without addition to the facts contained in the premises. It infers no more than is strictly involved in the facts contained in the premises, which it thus unfolds or explicates. This is the opposite of ampliative inference, in which, in endeavoring to frame a representation, not merely of the facts contained in the premises, but also of the way in which they have come to present themselves, we are led to add to the facts directly observed. Thus, if I see the full moon partly risen above the horizon, it is absolutely out of my power not to imagine the entire disk as completed, and then partially hidden; and it will be an addition to and correction of this idea if I then stop to reflect that since the moon rose last the hidden part may have been torn away; the inference that the disk of the moon is complete is an irresistible ampliative inference. All the demonstrations of mathematics proceed by explicative inferences. — Fermatian inference. See Fermatian. — Hypothetic inference, the inference that a hypothesis, or supposition, is true because its consequences, so far as tried, have been found to be true; in a wider sense, the inference that a hypothesis resembles the truth as much as its consequences have been found to resemble the truth. Thus, Schliemann supposes the story of Troy to be historically true in some measure, on account of the agreement of Homer’s narrative with the findings in his excavations, all of which would be natural results of the truth of the hypothesis. — Immediate inference. See immediate. — Incomplete inference. See complete inference, above. — Indirect inference, any inference reposing on the principle that the consequence of a consequence is itself a consequence. The same inference will be regarded as direct or indirect, according to the degree of importance attached to the part this principle plays in it. Example: All men die; but if Enoch and Elijah died, the Bible errs; hence, if Enoch and Elijah were men, the Bible errs. — Inductive inference. See induction, 5. — Inference of transposed quantity, any inference which reposes on the fact that a certain lot of things is infinite in number, so that the inference would lose its cogency were this not the case. The following is an example: Every Hottentot kills a Hottentot; but nobody is killed by more than one person; consequently, every Hottentot is killed by a Hottentot. If the foolish first premise is supposed to hold good of the finite number of Hottentots who are living at any one time, the inference is conclusive. But if the infinite succession of generations is taken into account, then each Hottentot might kill a Hottentot of the succeeding generation, say one of his sons, yet many might escape being killed.Tetrast Note 1: Peirce previously discussed inference of transposed quantity in 1881: Google on "Peirce" "every Texan kills". End of note. — Leading principle of inference, the formula of the mental habit governing an inference. — Necessary inference, an explicative inference in which it is logically impossible for the premises to be true without the truth of the conclusion.Tetrast Note 2: Peirce had necessary inference and probable inference together forming a dichotomy of almost all inferences, omitting non-explicative deductions.
Probable inference had three subdivisions:
—deduction of a mathematically probable conclusion,
—induction, &
—abduction.
Necessary inference was deduction of a conclusion both
(a) explicative (not plainly redundant) and
(b) not merely probable.
But, by the 1900s, he regarded abduction as seeking to be plausible rather than probable in an inductive sense. By that standard, deductions of optimal and feasible cases ought also to be classed as plausible inferences. Mathematics of optimization (longer known as linear and nonlinear programming) was not yet a discipline while Peirce lived. Also in later years he ascribed verisimilitude (which he also called likelihood) to worthwhile inductions. On such distinctions in general, see my Plausibility, verisimilitude, novelty, nontrivialness, versus optima, probabilities, information, facts.. End of note. — Probable inference, a kind of inference embracing all ampliative and some explicative inference, in which the premises are recognized as possibly true without the truth of the conclusion, but in which it is felt that the reasoner is following a rule which may be trusted to lead him to the truth in the main and in the long run. — Ricardian inference, the mode of inference employed by Ricardo to establish his theory of rent. See Ricardian. — Statistical inference, an inference in regard to the magnitude of a quantity, where it is concluded that a certain value is the most probable, and that other possible values gradually fall off in probability as they depart from the most probable value. All of the inferences of those sciences which are dominated by mathematics are of this character. = Syn. Analysis, Anticipation, Argument, Argumentation, Assay, Assent, Assumption, Conclusion, Conjecture, Conviction, Corollary, Criterion, Decision, Deduction, Demonstration, Dilemma, Discovery, Elench, Enthymeme, Examination, Experiment, Experimentation, Finding, Forecast, Generalization, Guess, Hypothesis, Illation, Induction, Inquiry, Investigation, Judgment, Lemma, Moral, Persuasion, Porism, Prediction, Prevision, Presumption, Probation, Prognostication, Proof, Ratiocination, Reasoning, Research, Sifting, Surmise, Test, Theorem, Verdict. Of these words, illation is a strict synonym for inference in the first and principal meaning of the latter word, but is pedantic and little used. Reasoning has the same meaning but is not used as a relative noun with of; thus, we speak of the inference of the conclusion from the premises, and of reasoning from the premises to the conclusion. A reasoning may consist of a series of acts of inferences. Ratiocination is abstract and severe reasoning, involving only necessary inferences. Conclusion differs from inference mainly in being applied preferentially to the result of the act called inference; but conclusion would further usually imply a stronger degree of persuasion than inference. Conviction and persuasion denote the belief attained, or its attainment, from a psychological point of view, while inference, illation, reasoning, ratiocination, and conclusion direct attention to the logic of the procedure. Conviction is perhaps a stronger word than persuasion, and more confined to serious and moral inferences. Discovery is the inferential or other attainment of a new truth. Analysis, assay, examination, experiment, experimentation, inquiry, investigation, and research are processes analogous to inference, and also involving acts of inference. Anticipation, assent, assumption, and presumption express the attainment of belief either without inference or considered independently of any inference. Presumption is used for a probable inference or for the ground of it. Argument, argumentation, demonstration, and proof set forth the logic of inferences already drawn. Criterion and test are rules of inference. Elench is that relation between the premises which compels assent to the conclusion; it is translated “evidence” in Heb. xi. 1, where an intellectual conclusion is meant. Corollary, deduction, dilemma, enthymeme, forecast, generalization, induction, lemma, moral, porism, prediction, prevision, prognostication, sifting, and theorem are special kinds of inference. (See those words). Conjecture, guess, hypothesis, and surmise are synonyms of inference in its secondary sense. Guess and surmise are weaker words.
The following is “induction, 5.” in the first edition, 1889–91, CD volume 3, CD part 11 Ihleite – Juno, CD page 3068. Peirce was in charge of the CD’s definition of induction, per the list of words compiled by the Peirce Edition Project’s former branch at the Université de Québec à Montréal (UQÁM).
induction […] 5. In logic, the process of drawing a general conclusion from particular cases; the inference from the character of a sample to that of the whole lot sampled. Aristotle’s example is: Man, the horse, and the mule are animals lacking a gall-bladder; now, man, the horse, and the mule are long-lived animals; hence, all animals that lack the gall-bladder are long-lived. Logicians usually make it essential to induction that it should be an inference from the possession of a character by all the individuals of the sample to its possession by the whole class; but the meaning is to be extended so as to cover the case in which, from the fact that a character is found in a certain proportion of individuals of the sample, its possession by a like proportion of individuals of the whole lot sampled is inferred. Thus, if one draws a handful of coffee from a bag, and, finding every bean of the handful to be a fine one, concludes that all the beans in the bag are fine, he makes an induction; but the character of the inference is essentially the same if, instead of finding that all the beans are fine, he finds that two thirds of them are fine and one third inferior, and thence concludes that about two thirds of all the beans in the bag are fine. On the other hand, induction, in the strict sense of the word, is to be distinguished from such methods of scientific reasoning as, first, reasoning by signs, as, for example, the inference that because a certain lot of coffee has certain characters known to belong to coffee grown in Arabia, therefore this lot grew in Arabia; and, second, reasoning by analogy, where, from the possession of certain characters by a certain small number of objects, it is inferred that the same characters belong to another object, which considerably resembles those objects named, as the inference that Mars is inhabited because the earth is inhabited. But the term induction has a second and wider sense, derived from the use of the term inductive philosophy by Bacon. In this second sense, namely, every kind of reasoning which is neither necessary nor a probable deduction, and which, though it may fail in a given case, is sure to correct itself in the long run, is called an induction. Such inference is more properly called ampliative inference. Its character is that, though the special conclusion drawn might not be verified in the long run, yet similar conclusions would be, and in the long run the premises would be so corrected as to change the conclusion and make it correct. Thus, if, from the fact that female births are generally in excess among negroes, it is inferred that they will be so in the United States during any single year, a probable deduction is drawn, which, even if it happens to fail in the special case, will generally be found true. But if, from the fact that female births are shown to be in excess among negroes in any one census of the United States, it is inferred that they are generally so, an induction is made, and if it happens to be false, then on continuing that sort of investigation, new premises will be obtained from other censuses, and thus a correct general conclusion will in the long run be reached. Induction, as above defined, is called philosophical or real induction, in contradistinction to formal or logical induction, which rests on a complete enumeration of cases and is thus induction only in form. A real induction is never made with absolute confidence, but the belief in the conclusion is always qualified and shaded down. Socratic induction is the formation of a definition from the consideration of single instances. Mathematical induction, so called, is a peculiar kind of demonstration introduced by Fermat, and better termed Fermatian inference. This demonstration, which is indispensable in the theory of numbers, consists in showing that a certain property, if possessed by any number whatever, is necessarily possessed by the number next greater than that number, and then in showing that the property in question is in fact possessed by some number, N; whence it follows that the property is possessed by every number greater than N.
Socrates used a kind of induccion by asking many questions, the whiche when thei were graunted he broughte thereupon his confirmacion concerning the present controversie; which kinde of argument hath his name of Socrates himself, called by the learned Socratic induction.
Sir T. Wilson, Rule of Reason.Our memory, register of sense,
And mould of arts, as mother of induction.
Lord Brooke, Human Learning (1633), st. 14.Inductions will be more sure, the larger the experience from which they are drawn.
Bancroft, Hist. Const. I. 5.
The following is “hypothesis, 4.” in the first edition, 1889–91, CD volume 3, CD part 10 Halve – Iguvine, CD page 2959. Peirce was in charge of the CD’s definition of hypothesis, per the list of words compiled by the Peirce Edition Project’s former branch at the Université de Québec à Montréal (UQÁM).
hypothesis […]. 4. The conclusion of an argument from consequent and antecedent; a proposition held to be probably true because its consequences, according to known general principles, are found to be true; the supposition that an object has a certain character, from which it would necessarily follow that it must possess other characters which it is observed to possess. The word has always been applied in this sense to theories of the planetary system. Kepler held the hypothesis that Mars moves in an elliptical orbit with the sun in one focus, describing equal areas in equal times, the ellipse having a certain size, shape, and situation, and the perihelion being reached at a certain epoch. Of the three coordinates of the planet’s position, two, determining its apparent position, were directly observed, but the third, its varying distance from the earth, was the subject of hypothesis. The hypothesis of Kepler was adopted because it made the apparent places just what they were observed to be. A hypothesis is of the general nature of an inductive conclusion, but it differs from an induction proper in that it involves no generalization, and in that it affords an explanation of observed facts according to known general principles. The distinction between induction and hypothesis is illustrated by the process of deciphering a despatch written in a secret alphabet. A statistical investigation will show that in English writing, in general, the letter e occurs far more frequently than any other; this general proposition is an induction from the particular cases examined. If now the despatch to be deciphered is found to contain 26 characters or less, one of which occurs much more frequently than any of the others, the probable explanation is that each character stands for a letter, and the most frequent one for e: this is hypothesis. At the outset, this is a hypothesis not only in the present sense, but also in that of being a provisional theory insufficiently supported. As the process of deciphering proceeds, however, the inferences become more and more probable, until practical certainty is attained. Still the nature of the evidence remains the same; the conclusion is held true for the sake of the explanation it affords of observed facts. Generally speaking, the conclusions of hypothetic inference cannot be arrived at inductively, because their truth is not susceptible of direct observation in single cases; nor can the conclusions of inductions, on account of their generality, be reached by hypothetic inference. For instance, any historical fact, as that Napoleon Bonapart once lived, is a hypothesis; for we believe the proposition because its effects — current tradition, the histories, the monuments, etc. — are observed. No mere generalization of observed facts could ever teach us that Napoleon lived. Again, we inductively infer that every particle of matter gravitates toward every other. Hypothesis might lead to this result for any given pair of particles, but could never show that the law is universal. The chief precautions to be used in adopting hypotheses are two: first, we should take pains not to confine our verifications to certain orders of effects to which the supposed fact would give rise, but to examine effects of every kind; secondly, before a hypothesis can be regarded as anything more than a suggestion, it must have produced successful predictions. For example, hypotheses concerning the luminiferous ether have had the defect that they would necessitate certain longitudinal oscillations to which nothing in the phenomenon corresponds; and consequently these theories ought not to be held as probably true, but only as analogues of the truth. As long as the kinetical theory of gases merely explained the laws of Boyle and Charles, which it was constructed to explain, it had little importance; but when it was shown that diffusion, viscosity, and conductibility in gases were connected and subject to those laws which theory had predicted, the probability of the hypothesis became very great.
I asked him what he thought of Locusts, and whether the History might not be better accounted for, supposing them to be the winged Creatures that fell so thick about the Camp of Israel? but by his answer it appear’d that he had never heard of any such Hypothesis.
Maundrell, Aleppo to Jerusalem, p. 61.We have explained the phænomena of the heavens and of our sea by the power of gravity. . . . . But hitherto I have not been able to discover the cause of those properties of gravity from phænomena, and I frame no hypothesis; for whatever is not deduced from the phænomena is to be called an hypothesis; and hypotheses, whether metaphysical or physical, whether occult qualities or mechanical, have no place in experimental philosophy.
Newton, Principia (tr. by Motte), iii.
The following is from Peirce’s 1908 discussion of the idea of simpler hypothesis, from near the end of IV in “A Neglected Argument for the Reality of God” (via Wikisource with added good notes), originally published (incompletely) in Hibbert Journal v. 7 and less incompletely in Collected Papers v. 6 and Essential Peirce v. 2. For the whole essay go to https://gnusystems.ca/CSPgod.htm#na0. By “il lume naturale” is understood “the natural light of reason”.
- posted by The Tetrast @ 12:52 PM 0 commentsModern science has been builded after the model of Galileo, who founded it on il lume naturale. That truly inspired prophet had said that, of two hypotheses, the simpler is to be preferred; but I was formerly one of those who, in our dull self-conceit fancying ourselves more sly than he, twisted the maxim to mean the logically simpler, the one that adds the least to what has been observed, in spite of three obvious objections: first, that so there was no support for any hypothesis; secondly, that by the same token we ought to content ourselves with simply formulating the special observations actually made; and thirdly, that every advance of science that further opens the truth to our view discloses a world of unexpected complications. It was not until long experience forced me to realise that subsequent discoveries were every time showing I had been wrong,— while those who understood the maxim as Galileo had done, early unlocked the secret,— that the scales fell from my eyes and my mind awoke to the broad and flaming daylight that it is the simpler Hypothesis in the sense of the more facile and natural, the one that instinct suggests, that must be preferred; for the reason that unless man have a natural bent in accordance with nature’s, he has no chance of understanding nature at all. Many tests of this principal and positive fact, relating as well to my own studies as to the researches of others, have confirmed me in this opinion; and when I shall come to set them forth in a book, their array will convince everybody. Oh no! I am forgetting that armour, impenetrable by accurate thought, in which the rank and file of minds are clad! They may, for example, get the notion that my proposition involves a denial of the rigidity of the laws of association: it would be quite on a par with much that is current. I do not mean that logical simplicity is a consideration of no value at all, but only that its value is badly secondary to that of simplicity in the other sense.
. . . . |